
I watched an engineer close a laptop with a look that meant the demo had crossed a line. You feel that small electric twinge — the moment a tool stops being clever and starts being unsettlingly capable. That’s the atmosphere around Google’s new Gemini 3.1 Pro.
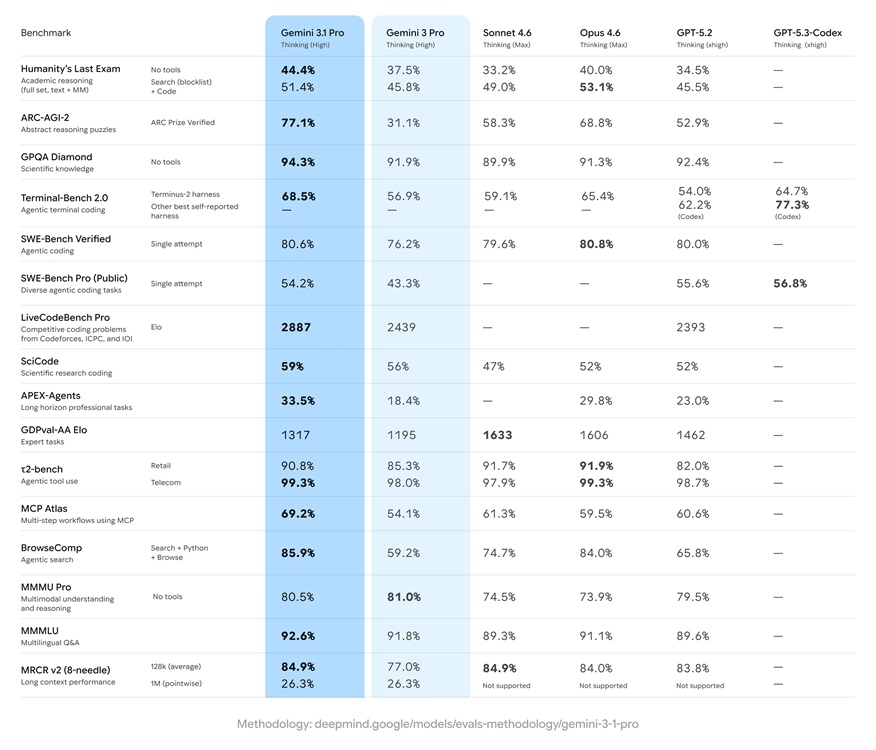
I’ve read the release notes and stared at the numbers so you don’t have to. Google says Gemini 3.1 Pro is a clear step up from Gemini 3 Pro, trading polish for real gains in multi-step reasoning and multimodal work. You’ll see it rolling into the Gemini app, NotebookLM, Google AI Studio, Antigravity, and the Vertex API while it sits in preview.
In a lab meeting the whiteboard reads “ARC-AGI-2”: Gemini 3.1 Pro Scored Over 77% on ARC-AGI-2
Google reports that Gemini 3.1 Pro hit 77.1% on the ARC-AGI-2 benchmark. That’s a headline number because ARC-AGI-2 is designed to probe novel reasoning, not just memorized facts. For context, Anthropic’s Claude Opus 4.6 scored 68.8% on the same test, according to public comparisons.
On Humanity’s Last Exam — a tough no-holds-barred challenge — Gemini 3.1 Pro scored 44.4% without tools and 51.4% when allowed to use search and coding utilities. Those tool-assisted gains matter: they show how the model behaves when plugged into workflows, not just when it’s answering isolated prompts.
A researcher’s notebook lists “GPQA Diamond”: Scientific reasoning appears stronger — and faster
The GPQA Diamond benchmark, which stresses scientific knowledge, returned a 94.3% score for Gemini 3.1 Pro, placing it ahead of competitors on paper. If you care about accuracy in technical domains, that jump is a signal. The model also scored 80.6% on SWE-Bench Verified for agentic coding, barely behind Claude Opus 4.6’s 80.8%, suggesting Google focused improvements where engineers care most.
How does Gemini 3.1 Pro stack up against OpenAI’s GPT-5.3-Codex and ChatGPT models?
OpenAI’s recent moves — ChatGPT 5.2 and the GPT-5.3-Codex release — aim directly at agentic coding and multi-step planning. Google’s numbers position Gemini 3.1 Pro as a strong challenger in reasoning and multimodal tasks. If you’re choosing a model for complex workflows that mix images, code, and long tasks, the decision will come down to integration: Vertex API, NotebookLM, or the Gemini app versus OpenAI’s APIs and any proprietary tooling you already use.
A person at a desk asks “Where can I try it?”: Availability and real-world access
Gemini 3.1 Pro is currently in preview. Google says it’s appearing inside the Gemini app, NotebookLM, Google AI Studio, Antigravity demos, and through the Vertex API. That means early adopters and enterprise users will see it first — if you use Vertex or Google’s AI Studio, you’ll likely get hands-on access sooner than most.
Where can you access Gemini 3.1 Pro?
If you’re already in Google’s ecosystem, the path is plain: try the Gemini app or request preview access via Vertex API and Google AI Studio. NotebookLM will make it feel like a research assistant, and Antigravity showcases the multimodal and SVG animation strengths Google highlighted. If you’re on OpenAI or Anthropic stacks, cross-platform comparisons will be the next practical step.
I’ll say this plainly: the model behaves less like a flashy prototype and more like a tool you can fold into a process — like a veteran chess master who sees the endgame three moves early. Developers should care because that foresight changes how agentic systems are built.
A designer pins an SVG to the wall: multimodal work looks cleaner and more reliable
Google demoed animated SVGs and side-by-side comparisons with Gemini 3 Pro. The vector illustrations weren’t just prettier; they were materially different in structure and intent. For creative teams, that means fewer manual edits and more production-ready output from prompts. Think of Gemini 3.1 Pro as a Swiss Army knife for multi-step tasks — compact, varied, and oddly hard to replace once you start using it.
Is Gemini 3.1 Pro better at coding and following instructions?
Google reports improved instruction-following and stronger agentic coding performance. The SWE-Bench number shows it’s very competitive with Claude Opus on coding tasks, and the tool-assisted Humanity’s Last Exam score suggests it makes sensible use of search and code tools. If your work depends on long, chained reasoning or multi-agent orchestration, this model is worth testing.
Where this heads next is the drama: OpenAI has been iterating fast with GPT-5.3-Codex, Anthropic keeps tightening Claude, and Google is pushing the preview into core products. For you, the practical question is readiness — how quickly will your stack accept a model that can hold longer conversations, manipulate images, and call tools without losing the thread?
Which model would you bet your next product release on — the one that scores highest on a benchmark, or the one that actually fits cleanly into your team’s workflow?